A friend of ShipIndex.org contacted us to see if we know on anyone who might be interested in acquiring several excellent ship models, made by a professional modeler but for his own enjoyment. These models have been appraised and are in attractive display cases. They’re also in Tennessee, and transporting a ship model is no easy task, so keep that in mind.
Here’s an example of some of this artist’s models on display in a public library:
If you’d like to learn more, don’t hesitate to contact us at comments@shipindex.org, and we’ll connect you with the current owner of these models.
In this installment of maritime history events, we travel all around the world. If you’ve got an event that you think should be included, let us know in a comment below, or in an email to comments@shipindex.org.
March 9-10: The submarine USS Kete (Wikipedia, ShipIndex) engaged with three Japanese vessels while gathering weather data in preparation for the invasion of Okinawa, in 1945. Kete was built in Manitowoc, Wisconsin, and entered service in 1944. Kete was lost later in the month, but no information is known around what caused her loss. In 1995, deep-sea divers may have spotted Kete, but they were unable to confirm the identity of the submarine they found, and after their Remotely Operated Vessel was lost in 1997, they were unable to return to the site.
March 11: On board Balclutha (Wikipedia, ShipIndex, now at the San Francisco Maritime National Historic Park), in 1899, the Captain’s wife, Alice Durkee, gave birth to their daughter while at sea. The child was named Inda Frances, because she was born on the Indian Ocean, while headed for San Francisco. (source)
March 13: In 1808, HMS Emerald, a 36-gun frigate (Wikipedia, ShipIndex) with a long history in the British navy, took a large French schooner, Apropos (ShipIndex) in Viveiro harbor (on the coast in the northwest corner of Spain, in Galicia). The crew on Apropos had run their ship on shore to escape the British, but they were unable to do so, and eventually set the ship on fire, after having run off her crew. Emerald lost nine men, plus had 16 wounded, in the action.
March 14: On this day in 1790, William Bligh returned to Great Britain, after the mutiny against him on board HMS Bounty (Wikipedia, ShipIndex), the year before. Fletcher Christian, Bligh’s good friend and a master’s mate on Bounty, put Bligh and several other crew in a small boat, which Bligh successfully navigated on a 6700km open ocean voyage to Coupang, in Timor. Bligh eventually returned to Great Britain, and continued his naval career for another 25 years. Below is a photo I took of Capt Bligh’s grave and memorial, in what is now London’s Garden Museum, on Lambeth Palace Road, on a visit in 2023.
For more about these ships, check out ShipIndex.org. And let us know if you have events that you think we should include!
This blog post offers links and notes related to my live webinar presentation for ShipIndex.org users on October 18, 2023. It will be updated slightly after the presentation, to reflect any changes or discussions during the presentation. It’s not intended to represent all of the comments shared during the presentation, but instead to be a place where links and notes are stored, for the benefit of attendees.
Section 1. Using vessel research in genealogy – how it can be applied, and how it can benefit genealogy research
Important: Know what a resource can do: ShipIndex cannot really help you find information about a person, and the large genealogy databases cannot really help you find information about vessels. Use the right tool for the job!
Monongahela, the last tall ship to leave Seattle’s Lake Union before the completion of the Aurora Bridge. Photo hosted by Puget Sound Maritime Historical Society.
Vessel research can help you find an image of the ship an ancestor emigrated on, or perhaps a picture of the ship that grandparents took their honeymoon on.
For ancestors who served in the military, vessel research can help you learn about their experiences: if you know what ship they were on, and when, then researching the history of the ship will help you learn more about their experiences.
Vessel research might help you find a diary or logbook kept by someone who was on the voyage that your ancestor was on.
Section 2. Using vessel research in maritime and other history – not just genealogy
Research in local history can help learn a great deal from maritime history – researching the vessel, rather than the people on it. Perhaps you’re researching a schooner that’s been in the community for 70 years, but must be removed – such as Equator, in Everett, Washington.
Screenshot from Everett, Washington, HeraldNet.
Or you want to research the history of a vessel whose wreck was just discovered in Lake Superior:
Section 3. Using ShipIndex.org as a tool, among many, for doing this work
Introduction to ShipIndex, what it can and cannot do; comparing the free database and the subscription database.
‘Cards’ are used to differentiate between ships with the same name, and to bring together different names for the same ships. How does this work?
Some important details on searching within ShipIndex:
Remember that if you have a short ship name, like “James” or “Wasp”, there’s likely a whole set of other ship names to explore. The search returned an ‘exact match’, and if you click on “See other matching ships”, you’ll see many more with the ship name in it.
If that’s overwhelming, you can narrow down your search to only the ship name field, by searching "@ship_name james“, for example.
To limit a search to names that start with a term, use the carat (“^”) character, for example: “^james“
Section 4. Other options for vessel search, beyond ShipIndex
There are many ship registers available; not all are included in ShipIndex.org, since acquiring a list of their content can be quite difficult (or impossible!). Some examples:
Section 5. Ways of searching the free web most effectively
When using Google, try the “AROUND” function, with the vessel type – so, for example, “constellation AROUND(5) sloop-of-war” – very different results from just “constellation“!
Use citations from Wikipedia to discover great sources about those ships that have Wikipedia entries.
Section 6. Finding the books and journals you’ve identified
Using WorldCat.org to locate libraries that own a particular title – but consider the many challenges that come with searching WorldCat. It is not particularly reliable anymore. It’s very difficult to determine what library has a particular journal (ie, magazine) that you want. Become friends with your interlibrary borrowing partners! (And be sure to support them!)
Searching for manuscripts: During the session, I discussed the challenges of finding manuscript resources that are mentioned in WorldCat but list no location. This post from 2014 shows how to find the actual location of the manuscript collection, by searching the National Union Catalog of Manuscript Collections, or “NUCMC” (pronounced “nuck-muck”). The WorldCat interface has changed in the past ten years, but the underlying content, and issues around it, remains. I don’t know why WorldCat doesn’t show the location of these items, but it doesn’t. The post explains how to get around that.
Section 7. Searching for historical newspapers online – a great tool for learning more
The Ohio Memory project includes lists of, and links to, many Ohio newspapers — most 19th century ones come from the Library of Congress’ Chronicling America project.
If searching is possible, certainly give it a try, but many interfaces do not have good search functionality. Conversion to text can also be very bad, which limits searching.
For an amazing interface and project, see the remarkable California Digital Newspaper Collection. I’ve become slightly obsessed with correcting content here, and I’ve discovered that the San Francisco Call has numerous listings of vessel arrivals and departures across the West Coast.
Section 8. Using University Libraries to do further research (APPROACH #1 – with database access)
Many – but definitely not all – academic libraries will allow visitors to enter and use their databases. When librarians sign contracts to provide access to these expensive databases, we try to ensure access for “walk-in” users – for anyone who comes in to the library. This will especially be true for public academic libraries. If you have an academic library near you, ask if you can use most of its resources as a walk-in user.
ProQuest Historical Newspapers is a valuable resource when searching newspapers. Others include Accessible Archives, NewsBank, and more. In ProQuest, try using “NEAR” function: so, “monongahela NEAR oiler“. (Use NEAR/#, where # is the number of words. NEAR without a number defaults to 4 words.)
Section 9. Using University Libraries without access, from afar – it’s still doable, sort of! (APPROACH #2 – without database access)
“Discovery Layers” are a tool for searching much (but definitely not all) subscription databases, all at once. Content from many subscription databases is pre-indexed and users can search a lot of databases all at once, similar to using Google.
There are two main companies who offer Discovery Layers: ProQuest (in their Ex Libris division) and EBSCO. Each discovery layer does NOT include the content from its competitor. Since ProQuest has superior coverage of historical newspapers, find a major research library who uses the Ex Libris CDI and also allows you to search their discovery layer without logging in. This site shows which of the largest US & Canadian libraries use which discovery layer. Use a library in the “Ex Libris CDI” section because they will include ProQuest databases in the discovery layer. Select a university, then click on “Library Web Site,” and find the place to start searching.
Not all libraries will allow you to search without logging in, so if one doesn’t, try another. Yale will, for example, so they’re a great place to start. In the Yale interface, you can even narrow it down to just newspaper articles. BUT BUT BUT BUT — and this is important — you CANNOT get to the article itself, at least not here! Discovering that the article exists, however, might be incredibly valuable.
For more information about historical newspapers in a certain state or city, consider looking at the LibGuides about newspapers in the state or province at the largest university library, or the state library, for that state or province. For example, OSU, or State Library of Ohio.
Section 10. Searching for journals and newspapers
What do you do if you’ve found an article, or a journal, that isn’t available at the library near you? Your best option is probably interlibrary borrowing, but there are other options, as well.
Section 11. Conclusion.
I believe that vessel research can improve your family history, and the story you tell in your genealogy. Some of it might just be “adding leaves to the tree” — finding images of ships that were tangentially connected with your family story, and look good in a document or book you create. Others will directly inform your understanding of your ancestors’ lives, such as by learning about the battles those on board a warship (including your ancestor) during World War II, or during another conflict.
I hope that learning a bit about some ways of doing some of this research might be useful and helpful to you.
This blog post offers links and notes related to my live webinar presentation to the Ohio Genealogical Society on July 11, 2023. It will be updated slightly after the presentation, to reflect any changes or discussions during the presentation. It’s not intended to represent all of the comments shared during the presentation, but instead to be a place where links and notes are stored, for the benefit of attendees.
Section 1. Using vessel research in genealogy – how it can be applied, and how it can benefit genealogy research
Important: Know what a resource can do: ShipIndex cannot really help you find information about a person, and the large genealogy databases cannot really help you find information about vessels. Use the right tool for the job!
SS Imperator, also Berengaria. Source: Library of Congress, via Wikipedia
Vessel research can help you find an image of the ship an ancestor emigrated on, or perhaps a picture of the ship that grandparents took their honeymoon on.
For ancestors who served in the military, vessel research can help you learn about their experiences: if you know what ship they were on, and when, then researching the history of the ship will help you learn more about their experiences.
Vessel research might help you find a diary or logbook kept by someone who was on the voyage that your ancestor was on.
Section 2. Using vessel research in maritime and other history – not just genealogy
Research in local history can help learn a great deal from maritime history – researching the vessel, rather than the people on it. Perhaps you have a mid-19th century panorama of the city and you’d like to research some of the boats you see on it?
Portion of 1848 “Panorama of Progress,” by Charles Fontayne and William S. Porter, held at Cincinnati and Hamilton County Public Library.
Or you’re researching a schooner that’s been in the community for 70 years, but must be removed – such as Equator, in Everett, Washington.
Screenshot from Everett, Washington, HeraldNet.
Section 3. Using ShipIndex.org as a tool, among many, for doing this work
Introduction to ShipIndex, what it can and cannot do; comparing the free database and the subscription database.
‘Cards’ are used to differentiate between ships with the same name, and to bring together different names for the same ships. How does this work?
Options for doing advanced searching – see search features page for information about options on doing more advanced searching.
Section 4. Other options for vessel search, beyond ShipIndex
There are many ship registers available; not all are included in ShipIndex.org, since acquiring a list of their content can be quite difficult (or impossible!). Some examples:
Section 5. Ways of searching the free web most effectively
When using Google, try the “AROUND” function, with the vessel type – so, for example, “constellation AROUND(5) sloop-of-war” – very different results from just “constellation“!
Use citations from Wikipedia to discover great sources about those ships that have Wikipedia entries.
Section 6. Finding the books and journals you’ve identified
Using WorldCat.org (from OCLC, based in Dublin, Ohio) to locate libraries that own a particular title – but consider the many challenges that come with searching WorldCat. It is not particularly reliable anymore. It’s very difficult to determine what library has a particular journal (ie, magazine) that you want. Become friends with your interlibrary borrowing partners! (And be sure to support them!)
If you’re having problems with OCLC, try searching the OhioLINK central catalog, to see which academic libraries in Ohio have a particular title.
Section 7. Searching for historical newspapers online – a great tool for learning more
The Ohio Memory project includes lists of, and links to, many Ohio newspapers — most 19th century ones come from the Library of Congress’ Chronicling America project.
If searching is possible, certainly give it a try, but many interfaces do not have good search functionality. Conversion to text can also be very bad, which limits searching.
For an amazing interface and project, see the remarkable California Digital Newspaper Collection. I’ve become slightly obsessed with correcting content here, and I’ve discovered that the San Francisco Call has numerous listings of vessel arrivals and departures across the West Coast.
Section 8. Using University Libraries to do further research (APPROACH #1 – with database access)
Many – but definitely not all – academic libraries will allow visitors to enter and use their databases. When librarians sign contracts to provide access to these expensive databases, we try to ensure access for “walk-in” users – for anyone who comes in to the library. This will especially be true for public academic libraries. If you have an academic library near you, ask if you can use most of its resources as a walk-in user.
In Ohio, you have access to a range of databases via Ohio Web Library (though not, notably, ProQuest newspaper databases).
ProQuest Historical Newspapers is a valuable resource when searching newspapers. Others include Accessible Archives, NewsBank, and more. In ProQuest, try using “NEAR” function: so, “monongahela NEAR oiler“. (Use NEAR/#, where # is the number of words. NEAR without a number defaults to 4 words.)
Section 9. Using University Libraries without access, from afar – it’s still doable, sort of! (APPROACH #2 – without database access)
“Discovery Layers” are a tool for searching much (but definitely not all) subscription databases, all at once. Content from many subscription databases is pre-indexed and users can search a lot of databases all at once, similar to using Google.
There are two main companies who offer Discovery Layers: ProQuest (in their Ex Libris division) and EBSCO. Each discovery layer does NOT include the content from its competitor. Since ProQuest has superior coverage of historical newspapers, find a major research library who uses the Ex Libris CDI and also allows you to search their discovery layer without logging in. This site shows which of the largest US & Canadian libraries use which discovery layer. Use a library in the “Ex Libris CDI” section because they will include ProQuest databases in the discovery layer. Select a university, then click on “Library Web Site,” and find the place to start searching.
Not all libraries will allow you to search without logging in, so if one doesn’t, try another. Yale will, for example, so they’re a great place to start. In the Yale interface, you can even narrow it down to just newspaper articles. BUT BUT BUT BUT — and this is important — you CANNOT get to the article itself, at least not here! Discovering that the article exists, however, might be incredibly valuable.
For more information about historical newspapers in a certain state or city, consider looking at the LibGuides about newspapers in the state or province at the largest university library, or the state library, for that state or province. For example, OSU, or State Library of Ohio.
Section 10. Searching for journals and newspapers
What do you do if you’ve found an article, or a journal, that isn’t available at the library near you? Your best option is probably interlibrary borrowing, but there are other options, as well.
Section 11. Conclusion.
I believe that vessel research can improve your family history, and the story you tell in your genealogy. Some of it might just be “adding leaves to the tree” — finding images of ships that were tangentially connected with your family story, and look good in a document or book you create. Others will directly inform your understanding of your ancestors’ lives, such as by learning about the battles those on board a warship (including your ancestor) during World War II, or during another conflict.
I hope that learning a bit about some ways of doing some of this research might be useful and helpful to you.
This is the first of a few new blog posts. It’s April 1, April Fools Day, but there is, alas, no foolin’ around here. It’s just bad news, start to finish, with the WorldCat subject entity links that have been in the free ShipIndex database since 2009. Read on, to learn more.
When ShipIndex switched from a personal project to a real company, back in 2009, I put all of the citations that had been in the “project” database, into the free database. Anything new was going to go in to the subscription database. I had been in contact with researchers at OCLC, the very large library cooperative that ostensibly helps libraries manage their resources, and shares those holdings, via their publicly available database called WorldCat. I worked with several remarkable people there, who through the years generated a list of all of the “identities” for ships in WorldCat.
This meant we could find books or manuscripts that were by or about ships. So, a book about a ship is easy enough to imagine – the book The Royal Yacht Britannia: The Official History is clearly about that vessel. Having a specific subject heading about that specific yacht makes it easier to differentiate between vessels with the same name. It also created links to books by ships, which often meant logbooks our individually-kept personal journals by people who were on board a vessel. It was a great way of uncovering a lot of useful content about ships that wouldn’t be found otherwise.
But the folks at OCLC said this content needed to be in the free database, not in the then-nascent subscription database. That was fine with me; it was worth including that content and keeping it freely available. The file has been updated occasionally over the past few years, and has always been in the completely free database.
Two or three weeks ago, I was doing some searching, and looked at WorldCat records. I saw notices indicating that the OCLC Identities project, on which these links were based, was going away. This past week, all the links to WorldCat failed. OCLC has ended this project, and with it, links to lots of content that used to be in the database. They’ve also removed linking by Library of Congress Control Number. You’re just searching by phrase now – this seems like the total antithesis of the ideals behind Linked Data.
I have figured out a way to make these links mostly work. The links are now searching by subject headings, rather than by control numbers or identities. As a result, in many cases, they won’t work effectively. In the old file, there was a search to an identity for a ship named “104”, and it specifically went to the entry for a specific ship with that name. Now, the search is for any entry that has both terms “104” and “ship” in a subject heading, so instead of one or two specific results, you get 38 results. Some refer to ‘cruise 104’ of a different vessel. It’s really too bad. Searches for ships like “Mary” are going to terrible, because they’ll include ships named “Mary Rose”, “Mary Ellen”, “Mary & Frank”, “Mary Smith”, and any other ship that has ‘mary’ as just part of its name – instead of going directly to the ship you’re researching. A search for a single, common word ship name, like “Eagle” or “Union” or “James” or “Monitor” or “Wasp” is going to return any record that has that word anywhere in the list of subject headings, even if the term doesn’t have anything to do with a ship name. Connections we’ve made, between specific vessels represented in WorldCat and other citations for those specific vessels, are probably no longer relevant.
OCLC did some work in creating Virtual International Authority File (VIAF) records for some ships, as well. Again, this was great in differentiating between ships with different names. But as far as I can tell, that is also all wiped out.
I’m disappointed and frustrated by this change, as I am with most of what OCLC has done to WorldCat over the past few years.
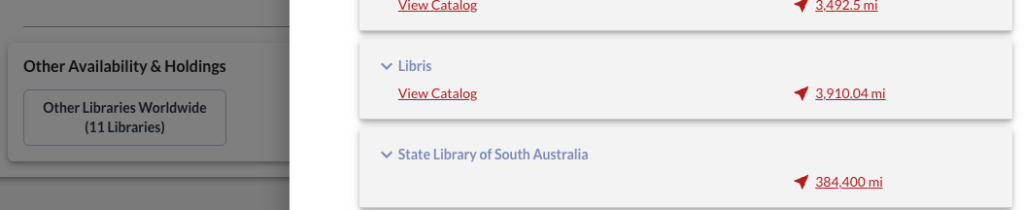
I’ll leave with this image I collected from WorldCat a few weeks ago, telling me that a copy of a book I wanted was at the State Library of South Australia, but that library is further than the distance to the moon:
My frustration with WorldCat – and OCLC – is ancient news, but it does just keep getting worse. This is really unfortunate. This is NOT a good April Fools joke.
OK, so “recently” isn’t necessarily accurate here; I think that this list covers content added in the past year, actually. We are always adding content to ShipIndex.org, but sometimes it’s slow going. So here’s a list of the content that has been added since my last content post,
New content:
Bunting, William Henry. Sea Struck.Thomaston, Maine: Tilbury House Publishers, 2016.
As you can see, it’s a lot of content, even if we haven’t been bragging about what we’ve added through the year. As always, please send a note to comments (at) shipindex.org if you know of a title that you think should be added to the database.
I updated the Merchant Vessels of the United States database today. That’s a big file (~375k entries) and it serves as an interesting collection of personal and merchant vessels.
(There’s a minor error in the import, in that about 10% of the entries – in the Os through Rs – are duplicated. I’m working on correcting that problem. Also, apologies about the layout in this blog post, particularly with the tables. Not sure what the problem is, but I’ll try to correct it.)
Unfortunately, the US Coast Guard has changed their system, and NOAA has dropped their version of the database altogether, so you can no longer link directly to a specific ship. This is very frustrating, but I can’t control other sites’ setups. The URL will take you to the search page, and you can search again for the ship name that you’d found in ShipIndex.
The Coast Guard has also removed tons of personal information about owners of recreational vessels. The remaining information will still be useful to some.
MVUS also creates an interesting opportunity to look at a really large data set, and get a good sense of what vessel names are most appealing to the most people in the US.
A few weeks ago I went through all of the online resources in ShipIndex.org, to see if they all worked. It’s not uncommon for interfaces and search structures to change, and the result is that URLs slightly change. Any change to a URL, however slight, will likely cause the link to break, however, so I wanted to review all of them, and fix the ones that I could.
In one instance, I thought that the resource had disappeared completely, but I got a very helpful reply from the folks running the site, I learned of the new URL structure, and was easily able to update those links. In another instance, I thought a different resource was gone for good, but after a bunch of searching was able to find it, and figure out an update. Some still need attention, and I’m still working on those.
Yesterday, however, I learned that some of the oldest links in the database, to Ship Registers and other resources at Mystic Seaport, no longer work. These worked when I checked two or three weeks ago, and have worked since they were loaded into the ShipIndex.org database in 2009, but not today.
The Research collection at Mystic Seaport has gotten an online overhaul, and the new online resources are in a different interface. While some like the new interface, and the old one certainly did need an update, it appears that we can no longer link directly to an entry for a ship. I’m checking with the staff at the library to see if that is, in fact, the case, but if so, I’ll have to take out about a million direct links to these ships. I’ll keep the ships in the ShipIndex database, because I can still say with certainty that these ships are mentioned in the resources at Mystic, but I won’t be able to take a user directly to the entries any more.
This has happened with other resources in the past, most notably (in my mind) the Ellis Island Ship Database. I find it frustrating, because I like providing direct links, and I think they’re easier for people to use and cite, but I guess it was done for a reason. In the past, one could save a URL, and use that to link directly to the resource. Now, you’ll need to repeat the search every time you want to get to that specific resource, and your citation will need to describe how to do the search, rather than just include the link to the page in question.
If I’m able to update these links to direct links at some point, I’ll certainly do so, but I doubt that’ll be possible.
ShipIndex.org is excited to announce our first publication(s)! We have three “Guides to Ships”, and each one introduces a different type of important vessel, with historic and modern images, and brief descriptions.
Each guide is a 12-panel, folded, laminated publication. They’ll hold up to rigorous use, and will be helpful in many different settings. They are each 9” by 4” when folded, and are a great size for slipping in your bag for the next trip to the port or the beach.
As an introduction, and for May 30 and May 31 ONLY, the guides are available at $2 off their regular price – for two days only, they’re just $5.95 a piece! A set of all three is available for $15.95, for the next two days only. On June 1, they’ll all return to their usual price. Standard shipping in the US remains FREE. Standard international shipping is an estimation of the actual shipping cost. And there’s no sales tax, except for residents of New York.
These are a great Fathers Day gift, though they won’t be at this price again. Stock up now!
The three guides are as follows:
Guide to Tall Ships: With a focus on square-rigged versus fore-and-aft-rigged ships, this guide explains terminology such as brigs, barks, barkentines, sloops, cutters, schooners, ketches, yawls, and more. It is illustrated with modern and historic photographs and paintings. The guide also has a map of significant maritime museums around the world.
Guide to Naval Ships: Highlights include a range of modern and historic naval ships, from battleships and aircraft carriers to patrol boats and cutters. The Guide to Naval Ships has images of modern and historic vessels from around the world, and particularly notes several naval museum ships.
Guide to Merchant Ships: This guide describes a wide range of merchant vessel types that one might see from shore, from oil tankers and roros (car carriers) to container ships and LNG carriers. Unusual ships, like orange juice carriers, livestock ships, and more, are also described and illustrated. Fishing vessels, ferries, and cruise ships round out the guide.
Each guide has a webpage associated with it, though as befitting the newness of the guides, the webpages aren’t yet complete.
Please check them out and let me know what you think. This is an introductory offer, and prices go back to the list price on June 1.
The Yale Center for British Art, in New Haven, CT, has two marine art-related exhibits coming up.
From Sept 15 to Dec 4, 2016, they’ll be hosting an exhibit titled “Spreading Canvas: Eighteenth-Century British Marine Painting“, which they say “is the first major exhibition to survey the tradition of marine painting that was inextricably linked to Britain’s rise to prominence as a maritime and imperial power, and to position the genre at the heart of the burgeoning British art world of the eighteenth century.”
Yale University Press will be publishing a fully-illustrated volume to accompany the exhibit.
At nearly the same time, and to complement the exhibit, the YCBA will host an exhibit titled “Yinka Shonibare MBE“, which will highlight the Nigerian artist’s work on Adm Nelson. The website describing the exhibit includes an image of Shonibare’s work, Nelson’s Ship in a Bottle, but it’s unclear to me if that work will be present. I’m a little unclear on it — perhaps they’ll have a smaller version of the work, as the original is quite large, and is now permanently (I thought) installed outside the National Maritime Museum in Greenwich.
Both mentions come via Enfilade, an online newsletter for Historians of Eighteenth-Century Art and Architecture (HECAA).