We are pleased to announce a new project at ShipIndex.org, which allows members of the public to share information about the vessels that matter to them. Do you have images, or documents, or details, about specific vessels? You can add that to a space where anyone can see and learn more about that ship.
Add pictures, links to websites, details that you have found, or anything else. Here’s how it works:
First, it’s important to know that we have ‘ship pages’ and ‘vessel pages’. A ship page is one that has results that are not narrowed down to a specific vessel. For example:

(This is a screen shot of the results page for ships named ‘Suzanna’, for someone who is logged in to the database.)
A vessel page is one that uses a unique identifier to bring together citations about one specific vessel. On some ship pages, you’ll see a lot of vessel cards, representing each of many different ships that have the same name. For example:

(Screen shot of multiple vessel cards on the ship page for ships named ‘Wasp’; each vessel card represents a different ship named ‘Wasp’.)
If you click on any of these vessel cards, you’ll get to a single page that has links to citations that refer only to that specific vessel, not to any others with that same name. (This approach also allows us to bring together the different names that one vessel might have over time.)

You’ll usually find an image of the vessel on that vessel page. Below the image, you’ll see a blue box that says “Comments”, and includes a circle with a number inside, indicating the comments that have been shared about that vessel. For example, see the box in the red circle, from this vessel card for RRS Discovery:
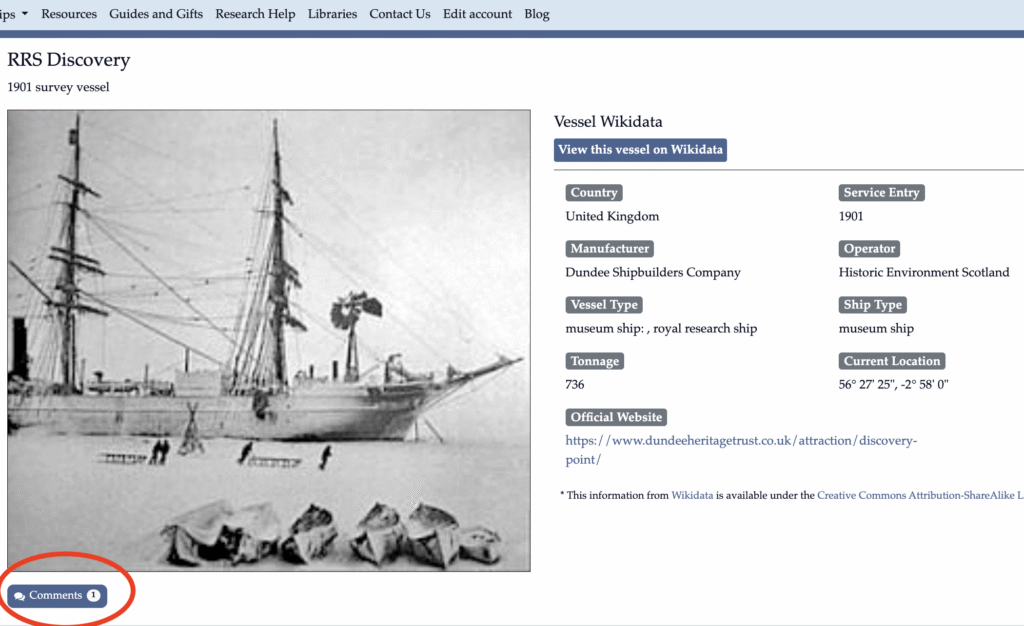
Click on the Comments button, and you’ll see all of the comments about that specific vessel. In this case, I’ve added a picture that I took of RRS Discovery, when I visited the ship in 2015.

If we don’t have a vessel page for the ship that you want to comment on, just email us at comments@shipindex.org, ask us to create that vessel page, and we’ll do it as quickly as we can.
Our commenting system is provided by Hyvor, an open-source commenting tool. You can create an account with Hyvor before logging in, or you can just post anonymously. Note that if your comment doesn’t relate to the ship in question, it’ll be quickly deleted.
Please share your ship knowledge with others! If you have a LOT to share, let us know, at comments@shipindex.org. Let’s see if we can arrange some way of making all of your content available to researchers around the world!





